在本篇博客中,我们将一步一步地构建一个使用 Pygame 作为渲染引擎的自定义 Gym 环境,并使用 Stable Baselines3 的 PPO 算法训练一个智能体。整个过程将涵盖环境的创建、智能体的定义、训练过程以及评估。让我们从最基础的窗口构建开始,逐步深入到完整的代码实现。
环境准备
确保已经安装了所需的库。使用以下主要库:
gymnasium: 用于创建和管理强化学习环境。pygame: 用于渲染图形界面。numpy: 进行数值计算。stable_baselines3: 提供强化学习算法实现。torch: 支持深度学习模型的训练。 使用以下命令安装这些库:
pip install gymnasium pygame numpy stable_baselines3 torch
创建 Pygame 窗口
建一个 Pygame 窗口,这是我们环境的可视化部分。Pygame 是一个流行的 Python 库,用于创建简单的游戏和图形界面。
- 初始化 Pygame:
pygame.init()初始化所有Pygame模块。 - 设置窗口: 使用
pygame.display.set_mode创建一个 800x600 像素的窗口,并设置标题。 - 主循环: 监听事件(如关闭窗口),填充背景颜色,并更新显示。
clock.tick(60)控制帧率为每秒 60 帧。
import pygame
# 初始化 Pygame
pygame.init()
# 设置窗口尺寸
screen_width = 800
screen_height = 600
screen = pygame.display.set_mode((screen_width, screen_height))
pygame.display.set_caption("Custom Gym Environment with Pygame")
# 设置时钟
clock = pygame.time.Clock()
# 主循环
running = True
while running:
for event in pygame.event.get():
if event.type == pygame.QUIT:
running = False
# 填充背景颜色
screen.fill((0, 0, 0)) # 黑色背景
# 更新显示
pygame.display.flip()
# 控制帧率
clock.tick(60)
# 退出 Pygame
pygame.quit()
定义自定义 Gym 环境
- 继承 gym.Env: 我们的自定义环境类继承自 gym.Env。
- 观察空间 (observation_space): 定义为一个 4 维的连续空间,包含玩家和目标的位置坐标。
- 动作空间 (action_space): 定义为离散的 4 个动作,分别对应上、下、左、右移动。
- Pygame 初始化: 设置窗口尺寸、标题以及时钟。
- 玩家和目标属性: 定义玩家的位置、大小和速度,以及目标的位置。
- 步数计数器: 用于限制每个回合的最大步数,防止训练陷入无限循环。
import gymnasium as gym
from gymnasium import spaces
import numpy as np
import random
class CustomPygameEnv(gym.Env):
metadata = {'render.modes': ['human']}
def __init__(self):
super(CustomPygameEnv, self).__init__()
# 定义观察空间:玩家位置 (x, y) 和目标位置 (x, y)
self.observation_space = spaces.Box(
low=0,
high=800, # 根据屏幕宽度和高度调整
shape=(4,), # [player_x, player_y, target_x, target_y]
dtype=np.float32
)
# 定义动作空间:上、下、左、右
self.action_space = spaces.Discrete(4)
# Pygame 初始化
pygame.init()
self.screen_width = 800
self.screen_height = 600
self.screen = pygame.display.set_mode((self.screen_width, self.screen_height))
pygame.display.set_caption("Custom Gym Environment with Pygame")
self.clock = pygame.time.Clock()
self.done = False
# 玩家属性
self.player_pos = [0, 0]
self.player_size = 50
self.player_speed = 5
# 目标位置
self.target_pos = [400, 300]
# 步数计数器
self.step_count = 0
self.max_steps = 2500
实现 reset 和 step 方法
reset 方法
- 重置环境状态,将 done 标志和步数计数器重置。
- 随机初始化玩家和目标的位置,确保它们在屏幕范围内。
- 返回初始观察状态和空信息字典。
def reset(self, seed=None, options=None):
super().reset(seed=seed)
print("重置环境")
self.done = False
self.step_count = 0
# 随机初始化玩家和目标点的位置
self.player_pos = [
random.randint(0, self.screen_width - self.player_size),
random.randint(0, self.screen_height - self.player_size)
]
self.target_pos = [
random.randint(0, self.screen_width - self.player_size),
random.randint(0, self.screen_height - self.player_size)
]
observation = self._get_state()
info = {}
return observation, info
step 方法
- 如果环境已经结束,直接返回当前状态和奖励为 0。
- 处理 Pygame 事件,监听是否关闭窗口。
- 根据动作更新玩家的位置(上、下、左、右)。
- 使用 np.clip 确保玩家不会移动出屏幕边界。
- 计算玩家与目标之间的欧几里得距离。
奖励函数
- 如果玩家到达目标位置,给予奖励 1,并结束回合。
- 否则,根据距离给予负奖励,距离越远,负奖励越大。
- 每一步额外给予微小的负奖励 -0.01,鼓励智能体尽快完成任务。
def step(self, action):
if self.done:
return self._get_state(), 0.0, True, False, {}
# 处理事件
for event in pygame.event.get():
if event.type == pygame.QUIT:
self.done = True
# 根据动作更新玩家位置
if action == 0: # 上
self.player_pos[1] -= self.player_speed
elif action == 1: # 下
self.player_pos[1] += self.player_speed
elif action == 2: # 左
self.player_pos[0] -= self.player_speed
elif action == 3: # 右
self.player_pos[0] += self.player_speed
# 边界检查
self.player_pos[0] = np.clip(self.player_pos[0], 0, self.screen_width - self.player_size)
self.player_pos[1] = np.clip(self.player_pos[1], 0, self.screen_height - self.player_size)
# 计算距离
player = np.array(self.player_pos, dtype=np.float32)
target = np.array(self.target_pos, dtype=np.float32)
distance = np.linalg.norm(player - target)
# 奖励函数
if distance < self.player_size:
reward = 1.0 # 到达目标点
terminated = True
else:
reward = -distance / (np.linalg.norm([self.screen_width, self.screen_height]))
terminated = False
# 步数惩罚
reward += -0.01
# 步数计数
self.step_count += 1
# 结束条件
truncated = False
if self.step_count >= self.max_steps:
truncated = True
self.done = True
return self._get_state(), reward, terminated, truncated, {}
实现渲染和辅助方法
在 Pygame 窗口中可视化玩家和目标,我们需要实现 render 方法和一些辅助方法。
render 方法
根据模式(默认为 'human')调用 _render_pygame 方法进行渲染。
def render(self, mode='human'):
if mode == 'human':
self._render_pygame()
close 方法:
退出 Pygame,释放资源。
def close(self):
pygame.quit()
_get_state 方法
渲染当前画面。 返回当前的观察状态,包括玩家和目标的位置。
def _get_state(self):
# 渲染画面
self._render_pygame()
# 返回状态:玩家位置和目标位置
return np.array(self.player_pos + self.target_pos, dtype=np.float32)
_render_pygame 方法
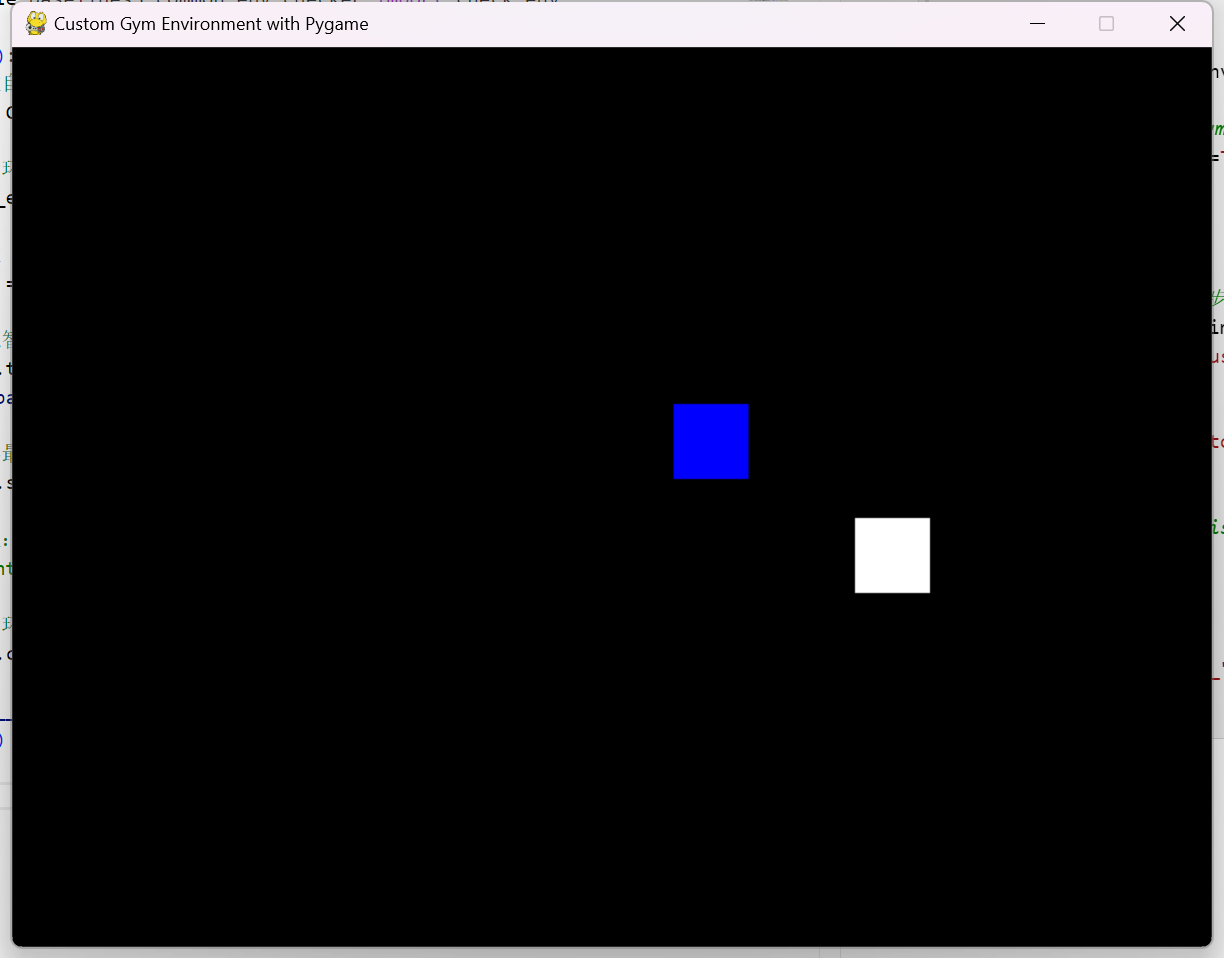
清空屏幕并填充黑色背景。 使用 pygame.draw.rect 绘制目标(蓝色)和玩家(白色)的矩形。更新显示并控制帧率。
def _render_pygame(self):
self.screen.fill((0, 0, 0)) # 黑色背景
# 绘制目标点(蓝色)
pygame.draw.rect(
self.screen,
(0, 0, 255),
pygame.Rect(self.target_pos[0], self.target_pos[1], self.player_size, self.player_size)
)
# 绘制玩家(白色)
pygame.draw.rect(
self.screen,
(255, 255, 255),
pygame.Rect(self.player_pos[0], self.player_pos[1], self.player_size, self.player_size)
)
pygame.display.flip()
self.clock.tick(60)
实现智能体 Agent 类
定义一个 Agent 类,负责加载、训练、保存和评估 PPO 模型。
导入需要的库
import torch
from stable_baselines3 import PPO
from stable_baselines3.common.env_checker import check_env
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common.callbacks import CheckpointCallback
初始化
使用DummyVecEnv和Monitor封装环境,便于Stable Baselines3进行多环境训练和监控。
检查是否有预训练模型路径,如果有则加载模型,否则创建新的PPO模型。
使用 GPU(如果可用)加速训练。
def __init__(self, env, model_path=None, tensorboard_log="./ppo_custom_tensorboard/"):
"""
初始化 Agent。
:param env: 训练的环境。
:param model_path: 如果提供,将加载现有的模型。
:param tensorboard_log: TensorBoard 日志保存路径。
"""
self.env = DummyVecEnv([lambda: Monitor(env)])
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
if model_path:
self.model = PPO.load(model_path, env=self.env, device=self.device)
print(f"加载模型来自 {model_path}")
else:
self.model = PPO(
'MlpPolicy',
self.env,
verbose=1,
learning_rate=3e-4,
tensorboard_log=tensorboard_log,
device=self.device
)
print("创建新的 PPO 模型")
训练
使用 CheckpointCallback 每隔一定步数保存一次模型,确保训练过程中不会丢失进度。
调用 self.model.learn 开始训练。
def train(self, total_timesteps=500000, save_interval=100000, save_path_prefix="ppo_custom_pygame_env"):
"""
训练智能体,并每隔 save_interval 步保存一次模型。
:param total_timesteps: 训练的总步数。
:param save_interval: 每隔多少步保存一次模型。
:param save_path_prefix: 模型保存路径的前缀。
"""
# 创建回调函数,每 save_interval 步保存一次模型
checkpoint_callback = CheckpointCallback(
save_freq=save_interval,
save_path='./models/',
name_prefix=save_path_prefix,
save_replay_buffer=False,
save_vecnormalize=False
)
# 训练智能体
self.model.learn(
total_timesteps=total_timesteps,
callback=checkpoint_callback
)
print("训练完成")
保存模型
使用 self.model.save 方法将模型保存到指定路径。
def save(self, path):
"""
保存模型。
:param path: 保存模型的路径。
"""
self.model.save(path)
print(f"模型已保存到 {path}")
评估模型
运行多个回合,记录并计算平均奖励,以评估智能体的表现。
def evaluate(self, episodes=10):
"""
评估智能体的表现。
:param episodes: 评估的回合数。
"""
obs = self.env.reset()
total_rewards = 0.0
for episode in range(episodes):
done = False
while not done:
action, _states = self.model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = self.env.step(action)
done = terminated or truncated
total_rewards += reward
average_reward = total_rewards / episodes
print(f"平均奖励: {average_reward}")
训练与评估智能体
- 创建环境: 实例化 CustomPygameEnv。
- 检查环境: 使用 check_env 确保自定义环境符合 Gymnasium 的规范,避免潜在的错误。
- 创建 Agent: 实例化 Agent 类,传入环境。
- 训练智能体: 调用 agent.train 方法,设置总训练步数和保存间隔。
- 保存最终模型: 训练完成后保存最终模型。
- 评估智能体: 可选步骤,评估智能体在多个回合中的表现。
- 关闭环境: 释放资源,关闭环境。
from stable_baselines3.common.env_checker import check_env
def main():
# 创建自定义环境
env = CustomPygameEnv()
# 检查环境是否符合 Gymnasium 的规范
check_env(env, warn=True)
# 创建 Agent
agent = Agent(env)
# 训练智能体,每10万步保存一次模型
agent.train(total_timesteps=500000, save_interval=100000, save_path_prefix="ppo_custom_pygame_env")
# 保存最终模型
agent.save("ppo_custom_pygame_env_final")
# 可选:评估智能体
# agent.evaluate(episodes=10)
# 关闭环境
agent.close()
if __name__ == "__main__":
main()